引言
端到端机器人学习卡在“三难”:仿真保真度不足带来 Sim2Real 失真、资产门槛与配置成本高难以规模化、数据采集慢导致训练效率低。此外,在端到端机器人学习中,“仿真到现实(Sim2Real)” 迁移性能下降依然是关键瓶颈。 根本原因在于:现有仿真环境与真实世界在外观、光照、几何结构等方面存在巨大差异, 导致训练出的策略在现实环境中泛化失败。
为了解决这一问题,研究者们尝试了多种类型的仿真框架,但各自存在明显局限。目前还没有一个框架能够同时做到高保真视觉建模、物理精确交互以及并行高效的可扩展性。这意味着,研究者虽然可以在视觉端生成精美的仿真环境,却无法确保这些环境在物理层面与真实世界一致;同样,拥有精准动力学的仿真系统,往往又缺乏足够的外观逼真度来支撑视觉学习。
在上述背景下,地瓜机器人联合清华大学、求之科技等提出具有关键意义的仿真器 DISCOVERSE。它首次在统一架构中融合了 3D Gaussian Splatting(3DGS)渲染器、MuJoCo 物理引擎与控制接口,构建出一个可扩展、模块化、开源的 Real2Sim2Real 机器人学习框架。 与DISCOVERSE相关的论文成果获得IROS 2025 Oral 。

◦ 论文标题: 《DISCOVERSE: Efficient Robot Simulation in Complex High-Fidelity Environments》
◦ 论文链接: https://arxiv.org/pdf/2507.21981v1
◦ 项目主页: https://air-discoverse.github.io/
◦ 收录情况:IROS 2025 Oral
针对端到端机器人学习的“三难”问题,DISCOVERSE给出统一答案:基于 3D Gaussian Splatting(3DGS) 的 Real2Sim2Real 框架能实现场景级+物体级双通道 Real2Sim 生成、与 MuJoCo 的物理耦合、多模态传感器原生支持,形成“高保真渲染 × 精准物理 × 大规模并行”的闭环,显著优于现有模拟器。
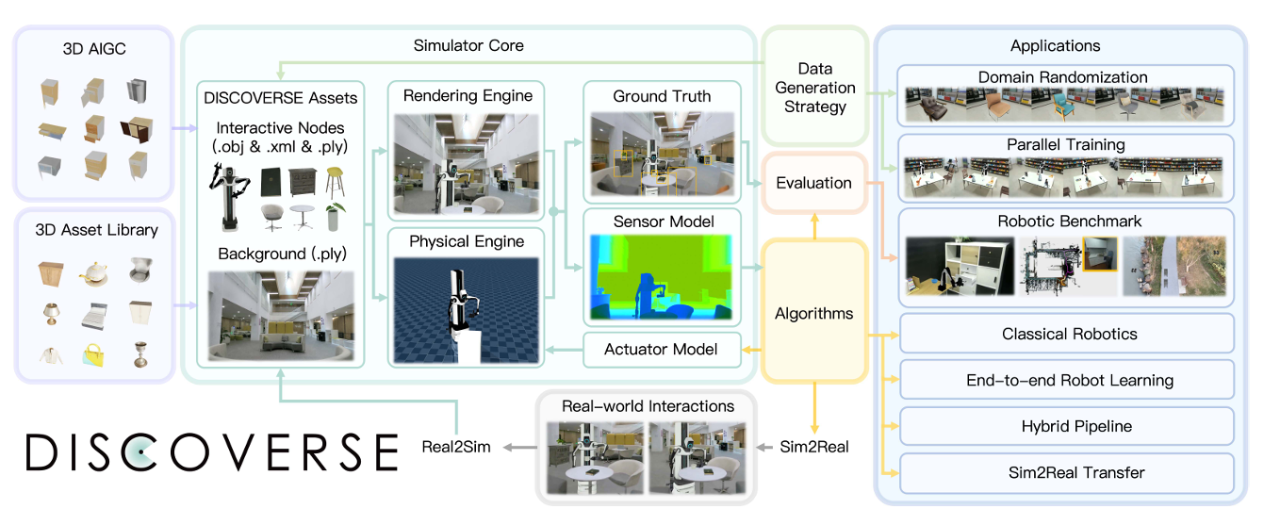
这一框架实现了视觉–物理–控制的全链路协同,支持场景级与物体级的高保真“现实到仿真”生成,并以数百 FPS 的高并行仿真能力,为机器人学习中的“Sim2Real gap”提供了系统性解决方案。
如何用“ Real2Sim2Real” 构建通用机器人仿真框架?
高保真仿真引擎
DISCOVERSE的底层核心是一个集渲染、物理与接口于一体的高保真引擎。它以 3D Gaussian Splatting(3DGS) 构建视觉世界,以 MuJoCo 驱动物理世界,并打通机器人控制接口,让“仿真器”第一次具备现实级的动态真实感。
• 视觉层:3DGS 渲染引擎,复刻真实外观
DISCOVERSE 使用基于 tile 的高斯光栅化方法,所有排序、splatting 与球谐函数计算均由自定义 CUDA 内核实现。在五路相机并行渲染下仍可达到 650 FPS 的实时速度,兼顾照片级真实感与高并行效率。
• 物理层:MuJoCo 动力学仿真,实现精准交互
该模块支持多关节机器人、复杂接触、摩擦与力控机制。无论是机械臂抓取、夹爪操作,还是复杂的动力学控制,都能在毫秒级物理步长中稳定求解。
• 控制层:桥接现实机器人,实现虚实共振
提供关节空间与笛卡尔空间 API,可直接与真实机器人通讯。仿真器不再是孤立实验环境,而是现实机器人学习与调试的“数字影子”。
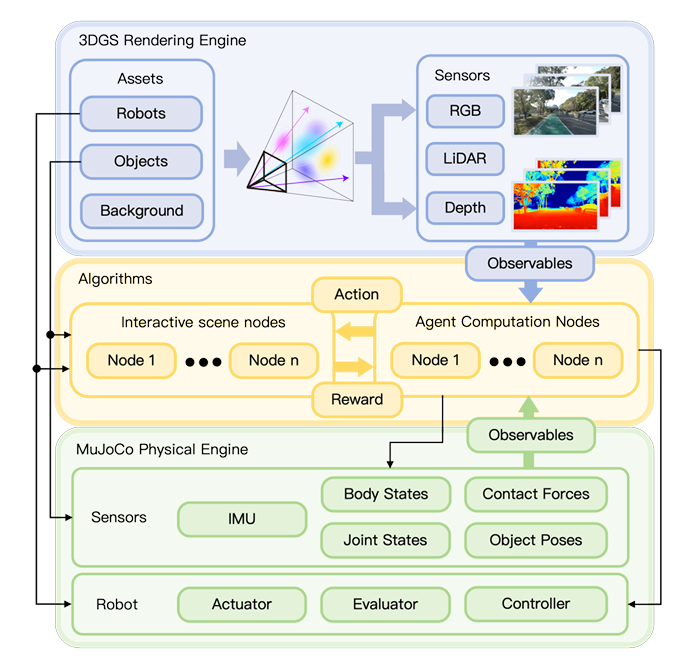
现实到仿真 Real2Sim
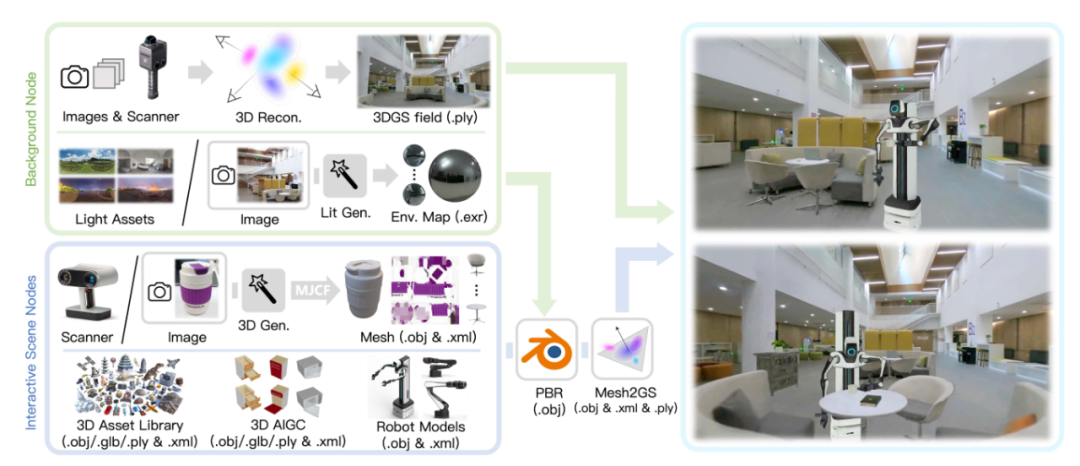
DISCOVERSE 的独特之处,在于它不仅“生成虚拟世界”,更能“复制现实世界”。它提出了 场景级 + 物体级双线 Real2Sim 管线,整合激光扫描、神经渲染与生成式光照重建,让仿真场景同时具备真实几何、可控光照与物理一致性。
• 场景级 Real2Sim:扫描现实,重建世界
通过 LixelK1 激光扫描仪获取几何正则信息,以 3DGS 表示生成稳健的辐射场。同时使用 DiffusionLight 从单张图像生成 HDR 环境贴图,恢复真实光照,提升全局视觉一致性。
• 物体级 Real2Sim:重建细节,强化交互
对朗伯物体采用 Artec Leo 多视角扫描; 对高光或薄结构物体,则使用 3D 生成模型CLAY从单图重建; 随后利用 Blender 进行离线 PBR 重光照,使物体外观与场景光照完全匹配。
• 统一格式与耦合:Mesh2GS 转换,实现视觉与物理融合
将带纹理网格通过自研 Mesh2GS 算法转化为高斯点云,实现“可渲染 + 可仿真”的双表示。从此,现实资产可直接进入仿真闭环,构成真正的 “Real2Sim2Real” 桥梁。
多模态感知与机器人接口
DISCOVERSE 不只是一个渲染器,而是一套“可感知、可交互、可迁移”的具身智能实验环境。通过多模态传感器模拟、执行器建模与端到端接口,它让仿真机器人具备现实级的感知与行动能力。
• 多模态感知:让机器人“看得真”
支持 RGB、深度、LiDAR、与 IMU 等传感器模拟。其中 LiDAR 模块采用 BVH 加速的高斯光线追踪框架,单机即可实现 >500 FPS,同时可叠加随机视频、光照增强与生成式噪声,实现域随机化训练。
• 执行与控制:让机器人“动得稳”
采用 MuJoCo 执行器模型模拟现实操作,真实还原“力—长度—速度”动力特性。
• 学习接口:让模型“学得快”
在 ACT 与 Diffusion Policy 实验中,其数据采集效率比真实机器人高出约 100 倍,实现真正意义上的“仿真提速、现实可迁移”。

实验结果分析
DISCOVERSE 在“模拟 + 真实”双场景、“多任务 + 多模态”维度下完成系统评测与应用验证。核心结论可概括为:跨仿真器稳赢、跨任务泛化、跨模态融合、零样本可迁移。整组实验体系包含四个互为支撑的层面:
• 模仿学习跨任务验证 —— 以三项接触密集的现实操作任务(关闭笔记本电脑、推鼠标、抓取猕猴桃)为代表,检验 DISCOVERSE 在不同仿真器间的可迁移性与视觉域一致性;
• 系统级对比实验 —— 通过多仿真器横向评测,量化 DISCOVERSE 在 3D 表示、物理建模、渲染保真度及场景复杂度上的综合性能;
• 传感器接口拓展实验 —— 验证 DISCOVERSE 在视觉、深度、LiDAR等模态下的统一仿真能力,展现其“全模态可感知”的特性;
• 应用层综合验证 —— 以导航、语义理解及空地协作为代表任务,展示框架在多形态具身智能体间的可扩展性与部署能力。
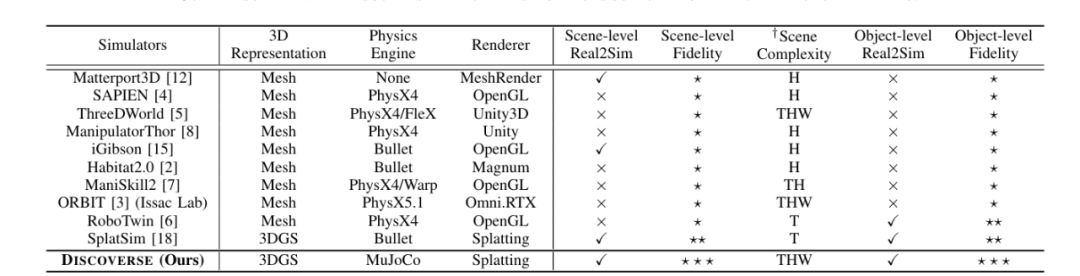
四组结果共同证明:DISCOVERSE 不只是一个仿真器,而是首个真正意义上贯通“Real2Sim + Sim2Real”全链条的通用具身智能平台。无论在视觉真实性、动力学一致性、感知完整性还是应用覆盖度上,它都显著超越了 MuJoCo、Isaac Lab、RoboTwin 与 SplatSim 等主流系统,成为推动“从仿真学习到现实智能”落地的关键基座。
跨任务验证: 从仿真到现实,真正“学得像、做得真”
DISCOVERSE定义了三个接触密集的现实操作任务: 关闭笔记本电脑、 推鼠标、 抓取猕猴桃。并分别在MuJoCo、RoboTwin、SplatSim 与 DISCOVERSE 中训练相同的模仿学习策略(ACT 与 Diffusion Policy),并零样本迁移至现实机械臂 AIRBOT Play 进行测试。
实验表明,DISCOVERSE 以超写实视觉输入和精确动力学建模,实现了显著的迁移性能提升:使用 ACT 策略时,DISCOVERSE 平均成功率较第二优的 SplatSim 提升约11%(无增强)、18.5%(含增强);使用 Diffusion Policy时,同样分别提升11%与11.4%;数据增强(随机视频叠加、HSV 随机化、Gamma 校正)使平均成功率再提升30%+。
实验结果如下表所示,结果证明,DISCOVERSE 生成的数据在视觉域与动力学域的逼真性,使策略能够在现实机器人上直接执行,无需微调。

系统级对比: 首个实现“Real2Sim + Sim2Real”双闭环的统一框架
传统仿真器要么强调物理精确(如 MuJoCo、Isaac Lab),要么追求渲染真实(如 Unreal、SplatSim),但始终无法兼顾几何还原、外观一致与物理耦合。DISCOVERSE 则通过 “3DGS + MuJoCo” 统一集成,打破了这一割裂。
此外,DISCOVERSE 的场景复杂度覆盖 “THW” 三层域:T(Tabletop)桌面操作、H(House-scale)室内导航、W( Wild-scale) 大型野外场景。这意味着研究者可在一个统一框架中完成从局部操作到大尺度探索的全域仿真研究,真正迈向“跨任务、跨场景、跨模态”的通用具身智能。
传感器拓展:多模态传感器与并行渲染能力
不同于以往仿真器仅聚焦视觉输入(如 RGB / 深度),DISCOVERSE 在传感器接口层实现了真正意义上的 “多模态全覆盖” ——从光学到几何、从视觉到力学,让仿真不再只是“看起来真实”,而是能被全面感知。
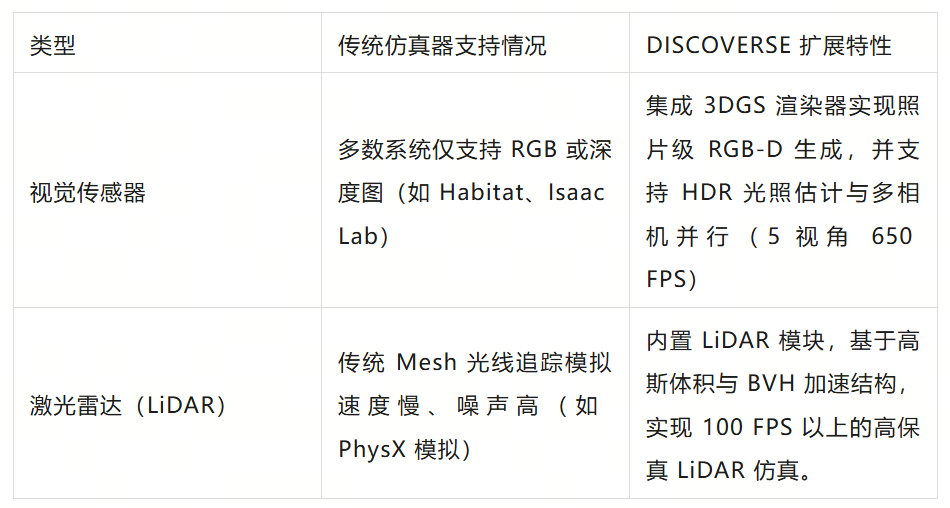
通过这一系列接口扩展,DISCOVERSE 不仅能重建外观,更能重建真实的感知链条:机器人“看到的”“摸到的”“测到的”,都与现实数据分布一致。这为跨模态学习、视觉-语言-动作融合(VLA)等任务提供了统一的实验基座。
应用层扩展:从机械臂到导航与协作的通用具身平台
除了操作任务外,DISCOVERSE 还展示了丰富的具身智能应用场景:

DISCOVERSE 的潜力不仅体现在实验指标的领先,更体现在其应用层的广泛适配性。得益于 3DGS 场景重建 + MuJoCo 物理仿真 + 实机接口 的统一设计,它在同一框架内即可支撑从精细操作到语义导航,再到跨平台协作的多类具身任务:
在操作领域,它可作为高保真的机器人操作试验场,支持机械臂、Dexterous Hand、多臂协作体等多类型智能体,实现从抓取、推移到装配的复杂交互。
在导航与理解领域,借助多模态渲染器与语义标注,DISCOVERSE 能驱动视觉语言导航与空间理解研究,为具身智能模型(如 VLA、NaVid 等)提供真实场景验证。
在多平台协作领域,通过空地一体的仿真接口,系统可同时支持轮式移动操作器与四旋翼无人机等多形态机器人,实现跨平台、跨视角的任务协同与场景探索。
这一“从精细控制到语义理解、从单体执行到多平台协同”的全链覆盖,使 DISCOVERSE 从一个仿真器,真正成长为通用具身智能研究的底层基础设施——在它之上,研究者可以同时研究控制、感知与语言的融合,并将算法直接推向现实世界的部署与验证。
关键结论与未来方向
核心结论
• 统一性:DISCOVERSE 是首个实现“3DGS × MuJoCo ” 完整闭环的 Real2Sim2Real 框架,从真实重建到高保真仿真再到物理部署,真正让具身智能研究进入全链路时代。
• 高保真与高效率兼得:借助高斯渲染与 CUDA 并行优化,系统在五相机 640×480 渲染条件下可达650 FPS,性能远超 Isaac Lab 等主流框架,兼具研究与工业部署价值。
• 跨模态融合能力:原生支持 RGB、深度、LiDAR、IMU等多模态传感器,让机器人能在统一环境中“看得真、测得全”。
• 通用适配性:无论是机械臂、移动操作器,还是四旋翼无人机与人形体,DISCOVERSE 均能无缝加载与控制,支撑从操作、导航到多机协作的多样化任务研究。
未来方向
• 从模仿学习走向强化与生成学习:未来版本将面向强化学习(RL)与世界模型(World Model)扩展,以实现零样本 Sim2Real 强化策略迁移。
• 更高精度的物理与光照建模:引入混合网格-高斯 PBR 渲染与软体动力学求解器,提升复杂接触、柔性物体与多光源场景下的仿真真实性。
• 大规模具身智能基准构建:基于 DISCOVERSE 构建包含操作、导航、语言交互的统一基准,推动从 “单任务评测” 向 “多模态、跨平台 Benchmark” 过渡。
• 开放生态共建:团队计划开放更多接口与资产库,让学术界与产业界共同参与 DISCOVERSE 的生态建设,打造新一代具身智能基础平台。
总结
DISCOVERSE 的出现,打破了机器人学习“仿真逼真度不足、现实迁移难落地”的长期僵局。它没有陷入“单纯堆叠模块、追求炫技”的误区,而是以3DGS 重建 → MuJoCo 物理 → 实机接口的统一逻辑,构建出一个真正贯通 “现实到仿真(Real2Sim)” 与 “仿真到现实(Sim2Real)” 的闭环体系。
这种设计让 DISCOVERSE 同时具备三大核心能力:像现实一样渲染、像物理一样运作、像平台一样扩展。它在视觉保真度上复现真实世界的光照与几何,在动力学仿真中捕捉反馈,并以模块化接口支持从机械臂操作到语义导航的多样具身任务。
对于追求可复现、可扩展、可迁移的机器人研究与工业部署而言,DISCOVERSE 提供了一条兼顾 研究深度 与 工程实用性 的新路径:研究者可以在仿真中生成真实感数据、验证控制策略、测试多模态模型,再将这些成果无缝迁移回现实机器人。
正如 3D 高斯 Splatting 曾重塑视觉重建,DISCOVERSE 正在重塑机器人仿真 ——它让“从现实学习现实”的梦想不再停留在论文里,而真正成为具身智能走向落地的关键起点与技术范本。